Global Sites

Global Sites
ChatGPTに“『ドキドキ文芸部!』キャラの出産怪文書”を何千回も生成させる奇人が、研究で観測される。57万件の匿名データでも隠しきれない性癖
同意したユーザーのChatGPTでの会話データを集積したコーパス「WildChat」に基づく新たな論文が公開。匿名データながら、あるユーザーが“『ドキドキ文芸部!』に関する二次創作”を数か月にわたって何千回も生成させていたことが観測されている。


ワシントン大学およびコロラド大学ボルダー校の研究者チームによる論文「AI Fiction in the Wild」が公開された。ChatGPTにおける50万件以上の匿名の会話データに基づく分析であり、このなかではあるヘビーユーザーが“『ドキドキ文芸部!』に関する二次創作”を数か月にわたって何千回も生成させていたという。このほかにも一部ユーザー間で、特定IPの二次創作を繰り返し求める傾向が確認されたそうだ。ITmediaなどが報じている。
今回の研究は、匿名化された50万件以上のChatGPTの英語ユーザーの会話データに基づき、「ユーザーがChatGPTでどの程度“フィクション”を生成しているのか、そしてどのような形式・傾向で生成しているのか」を分析するものだ。分析対象となるデータにはAllen Institute for AIの研究者らが構築したコーパス「WildChat」が用いられている。WildChatはAIコミュニティ「Hugging Face」上で公開された無料チャットボットを通じて収集されたデータセットだ。今回の分析では2023年4月から2024年5月にかけて収集された、WildChatの最初の公開データセットが用いられた。ユーザーはOpenAIアカウントを作成せずにGPT-3.5 TurboおよびGPT-4を利用できる一方、会話データが研究目的で公開・共有されうることに同意していた。
分析においては、データセットのうち英語での会話に絞った約57万3000件の会話データが用いられた。今回の研究は先述のとおりユーザーがどのように「フィクション」を生成しているのかを分析するものであり、まずは膨大なデータからフィクションを分類する作業が必要になったという。研究チームはGPT-o4-miniを用いて、フィクションについて「想像的上の内容や、現実世界の事実ではなく仮定に基づく内容」といった定義をおこなったうえで、実際のユーザーの会話を例示して同様の会話を分類。分類された会話から無作為に抽出したサンプル300件を手作業で精査し、高い精度で分類されていることを確認できたという。
結果として約57万件のうち、約19万5000件がフィクションとして分類されたという。そしてこのうち約5万2000件が「性的に露骨な内容(sexually explicit material)」であったとのこと。またデータセット上で有害(toxic)と判定されていた内容は6万7000件に及んだそうだ。つまりユーザーがChatGPTにて生成したフィクションの30%近くが、性的に露骨な内容を含む創作であったということだろう。
一方で分析ではフィクションに関連する会話は、ユーザーのごく一部に利用が集中していたことも示されている。研究によれば、フィクション関連の会話においては、上位2%のユーザーの会話が全体の80%以上を占めていたという。またフィクション関連の会話をおこなったユーザー数については、同一ユーザーが複数のIPアドレスから利用していた可能性などを考慮し、約1万と推定されている。つまり単純計算ではその上位2%である約200人が、15万件以上のフィクション関連の会話を生成していた概算となる。
またフィクション関連の会話を生成していたユーザーの傾向として、類似のプロンプトを何度も反復して利用するユーザーも一部見受けられたという。分析では一定期間同じ物語を反復して求め続けたうえで別の物語やトピックに移るユーザーがstory cyclersと分類されているほか、同じあるいは非常によく似た物語を長期間何度も要求し続けるユーザーがinfinite story demandersと分類されている。

そしてフィクション関連の会話を生成していたユーザーのうちもっとも多作であり、infinite story demandersとしてもっとも明確な例であるユーザーは、数か月にわたって何千回も『ドキドキ文芸部!』のファンフィクションの物語を生成し続けていたという。同作は文芸部に入部した主人公の男子高校生と、4人の女子部員たちとの交流を描く青春恋愛ADVとして始まるゲームだ。ただ公式では“サイコホラーゲーム”と謳われており、衝撃的な展開を見せることでも話題を呼んだ(関連記事)。
今回のユーザーは同作のキャラクター「ナツキ」が突然出産するという架空のシーンを“途中まで”ChatGPTに投げかけ、その続きを何千回にもわたって生成させていたとのこと。ChatGPTはたとえば救急隊員がかけつけて無事に出産を終えるといったハッピーエンドなど、さまざまな結末をユーザーに提示していたそうだ。そんなやりとりが何千回も繰り返されたようである。

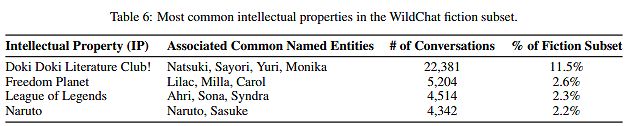
研究ではこのユーザーについてはとりわけ多作な外れ値であるとしつつも、多くの多作なユーザーは同じような流れで類似のフィクションを求めていたという。先述した上位2%のユーザーのプロンプトのうち、69%の割合で反復的なプロンプトが使用されていたそうだ。なおフィクション関連の会話において言及されていたIPのうち上位4作品も示されており、『ドキドキ文芸部!』が断トツで2万2381件、次いで『フリーダムプラネット』が5204件、『League of Legends』が4514件、「NARUTO」が4342件となっている。
なお今回の研究では先述したとおり、Hugging Face上で公開された無料チャットボットを通じて収集されたデータセット「WildChat」が用いられた。Hugging Faceは機械学習モデルやデータセットを共有するコミュニティであり、論文においては、チャットボットの利用者が平均的なユーザーよりも技術的なリテラシーが高く、オンライン文化により親しみのある層であった可能性も説明。WildChatはすべてのChatGPTユーザーの代表的なサンプルではないことが明言されている。またフィクション関連の会話をおこなったユーザー数についても匿名化されたデータに含まれるハッシュ化されたIPアドレスなどから、類似したプロンプトなどをもとに推定されている点にも注意が必要だろう。
一方でWildChatのデータセットは、機密性の高い“ChatGPTとユーザーとの会話”のサンプルとして貴重な分析対象となっているようだ。収集された50万件以上の会話のうち、30%以上が「フィクション」の生成を求めるものであり、またゲームなどを題材として反復的に同じような物語の生成が求められていたというのは興味深い。
今回の論文ではそうした一部ユーザーが、特定の物語に執着し、望ましい結果が得られるまで反復してプロンプトを微調整しながら用いていた傾向に着目。フィクションを含む芸術が本来、鑑賞者と作者の間で育まれていく本質的にコミュニケーション的で社会的な活動であったのに対して、生成AIによって他者との関わりがないままフィクションを作る文化が発達するといった、フィクションの“社会性の喪失”を最大の懸念点として挙げている。研究チームは今回の分析をAI時代における文学の変容が垣間見えるデータだとしており、ユーザーに直接話を訊きながら行動や動機を詳細に調べるといった、フィールドワークも交えたさらなる調査の必要性を説いている。



この記事にはアフィリエイトリンクが含まれる場合があります。
