

Since the emergence of image-generating AI such as ‘Midjourney’ and ‘Stable Diffusion,’ the concept of AI-generated content has led to widespread global attention, also bringing concerns about unauthorized machine learning. Recently, a dataset called MoeSpeech, hosted on Hugging Face, a platform that hosts datasets for machine learning, has caused controversial reactions in the Japanese community as it compiles the voices of numerous Japanese voice actors.
MoeSpeech is a dataset that contains approximately 363,000 voice files from 449 video game characters, totaling about 581 hours and 343GB. (source: Hugging Face) However, because it contains predominantly lines by Japanese voice actors, it has become a focal point of discussion in both technological and legal circles within Japan.
The dataset has received mixed reactions from the public. Some question the legality of extracting game data for AI analysis in the first place.
Others suggest that the legality of such datasets reflects problematic aspects of current copyright laws.
The heart of the controversy lies in the dataset’s creation and usage. Experts such as Taichi Kakinuma, a lawyer specializing in AI and a board member of the Database Society of Japan, have further explored the legal case.
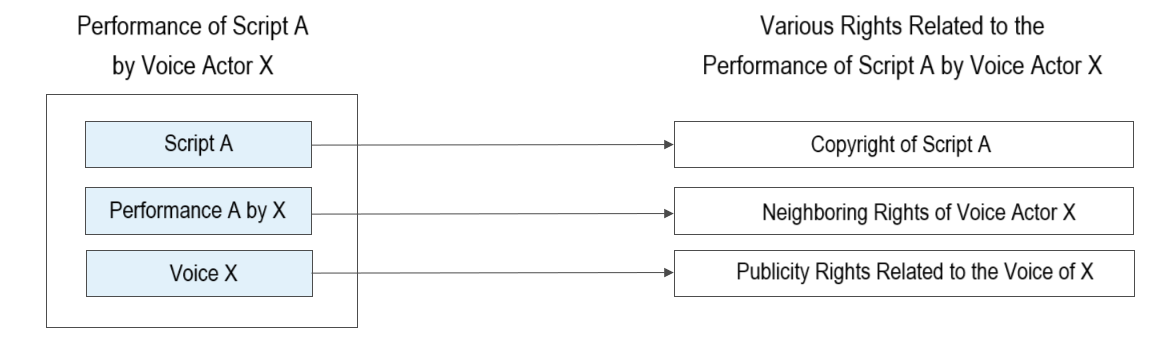
In this case, it seems that there are three types of rights involved:
- Copyright of the script, arising from the scriptwriter (or similar).
- Neighboring rights related to the performance of the voice actor.
- Publicity rights related to the voice of the voice actor.
The key question is the application of Article 30-4 of the Copyright Law, which applies when using data for the purpose of “information analysis.” This law allows for replicating copyrighted data for machine learning purposes, provided it’s not for enjoyment. Thus, the creation and public transmission of such datasets are principally covered by this article.
However, the issue is whether the act of creating and transmitting the dataset coexists with an “enjoyment purpose,” which would make the law inapplicable.
In this regard, Hugging Face has claimed:
“To prevent usage for enjoyment purposes, the following measures have been taken:
- Hiding game names and character names, not categorizing by games, and using random alphanumeric names for character identifiers.
- Randomizing the order of voice files in each character folder to prevent the identification of the sequence of lines.”
(translated into English, original version via Hugging Face)
However, the biggest area of debate is on publicity rights. Publicity rights, recognized in the Pink Lady Supreme Court decision on February 2, 2012, define the exclusive right to use one’s name, portrait, and so on to attract customers. This includes the voice, especially for voice actors or celebrities. Not all uses of such ‘portraits’ violate publicity rights, but potential unauthorized use of a voice actor’s identifiable voice could potentially constitute an infringement.
Regardless of the debate around legality, other people have commented on the ethical concerns of such technology, such as the harm it can cause to voice actors’ livelihoods.
If people outside of their circle don’t monitor and regulate to ensure proper use, they will endlessly expand the scope of harm.



