
「『スーパーマリオブラザーズ』をいろんな最新AIモデルにプレイさせる」研究報告。アクションゲームを遊ばせて見える“向き不向き”
米カリフォルニア大学の研究機関Hao AI Labによって、さまざまな最新モデルAIに『スーパーマリオブラザーズ』を遊ばせる研究の結果が報告された。モデルによっても、得意不得意があるようだ。
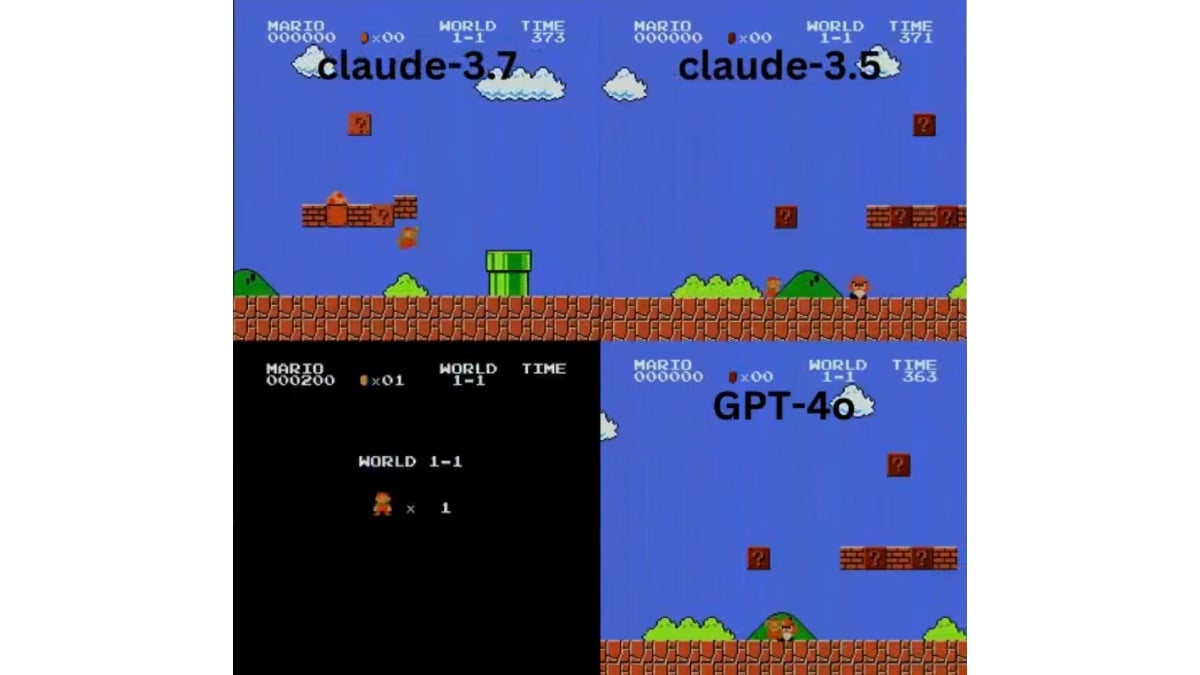
米カリフォルニア大学の研究機関Hao AI Labは3月1日、AIに『スーパーマリオブラザーズ』をプレイさせる取り組みの実験結果を公表した。近年、AI研究ではゲームへの応用が急速に発展しているが、その際の課題も徐々に明らかになってきている。
AIを用いたゲームプレイといえば、「Claude Plays Pokemon」が記憶に新しい。先日米Anthropicは、同社が開発するAIチャットモデル「Claude 3.7 Sonnet」を発表。「ハイブリッド推論モデル」と称されたこのモデルは、「通常モード」と「拡張思考モード」を自由に切り替えて使えるという特徴を持つ。簡単なタスクには素早く正確に答えつつ、難しい問題にはじっくり時間を使ってより精度の高い回答を導き出す、というような高い柔軟性が長所のようだ。その高い性能をアピールするため、Claudeに『ポケットモンスター 赤』(以下、ポケモン赤)をプレイさせる生配信をTwitchにて放送した(関連記事)。ちなみに、本稿執筆現在もなんとまだプレイ中である。
そんなAnthropicの『ポケモン赤』に対抗する形で、Hao AI Labは今回『スーパーマリオブラザーズ』をAIにプレイさせる実験をおこなった。同社は、Anthropicが試した『ポケモン赤』よりもリアルタイム性が求められるゲームにおいて、AIがどのような働きをするのかを示すことにしたという。なお、同社が開発したのはAIモデルではなく、エミュレーター上のゲームをAIに制御させるための「GamingAgent」というツールだ。
GamingAgentは、「障害物や敵に近づいたらジャンプして回避する」といった基本的な指示とゲーム画面を入力として与えると、ゲーム内のキャラクターを制御するPythonコードを出力するという仕組みになっているという。そしてGamingAgentではOpenAI・Anthropic・Googleの各社が手がけるAIモデルのAPIを利用することができ、ここには前述した「Claude 3.7 Sonnet」も含まれている。それぞれのモデルでの結果を比較することで、性能を測る実験が実施された。
今回もっとも優れたパフォーマンスを発揮したのはやはり高い柔軟性を持つ「Claude 3.7 Sonnet」だという。「Claude 3.7 Sonnet」は複雑な操作などもおこなえているようだ。次点として「Claude 3.5 Sonnet」が続いた。このモデルは安定した走りやジャンプを見せており、全体としてAnthropic製のモデルが優秀な結果を収めたようだ。「Claude」は特にソフトウェア開発などにおいて高い信頼性を獲得しており、Pythonコードを介して制御するというGamingAgentの構造と相性が良かったという可能性もある。
一方で、OpenAIの「o1」といった推論モデルではパフォーマンスが低かったという。推論モデルというのは、従来の学習モデルとは違った仕組みで答えを生成する新たなAIだ。自分の思考の過程をしっかりと出力し、それに基づいてより正確な回答を導くような仕組みを備えている。一般的には推論モデルのほうが従来型よりも高い精度を誇っているとされるが、その性質上、回答を出すまでの時間はより長い。今回の『スーパーマリオブラザーズ』といったリアルタイム性が求められるゲームには向いていないのではないかという分析がされている。『スーパーマリオブラザーズ』では、クリボーや穴を即座にジャンプするといった俊敏性がないと、そのままゲームオーバーに繋がってしまうからだ。リアルタイム性のあるゲームを上手にプレイするAIを作りだすためには、精度と速度を両立した進化を目指す必要があるといえる。
なお、『スーパーマリオブラザーズ』のプレイで優秀な結果を示したという「Claude 3.7 Sonnet」は、先述したとおりハイブリッド推論モデルだ。そしてGamingAgentのソースコードを確認してみると、今回の実験では「拡張思考モード」に切り替えるための「thinking」パラメーターが指定されていなかった。つまり今回は素早い出力が可能な「通常モード」で動作させていたと見られ、このことが優秀な成績に繋がったようだ。
ただし「Claude 3.7 Sonnet」における「通常モード」と「拡張思考モード」の切り替えは、運用する人間によっておこなう必要がある。また「拡張思考モード」では「thinking budget(思考予算)」を定めることで、どのくらい深く考えさせるかを指示することもできるが、現状それをAIが状況に応じて自律的にコントロールするところまでは到達していないようだ。もしもひとりでに思考方法を切り替えられる“真にハイブリッド”な推論モデルが登場したら、どのようなゲームプレイが見られるのか。今後自由に思考の切り替えができる推論モデルが登場した際には、「Claude 3.7 Sonnet」よりもさらに素早く、幅広いゲームを上手にプレイできるかもしれない。

また、発展途上にあるAIによるアクションゲームのプレイと比較して、すでにAIが目覚ましい進化を見せている囲碁などとの違いに触れたい。Google DeepMind社が開発した「AlphaGo」は2016年に当時のトップ棋士を破り、業界に大きな衝撃を与えた。囲碁にもリアルタイムに消費する持ち時間が存在するものの、『スーパーマリオブラザーズ』などが要求するリアルタイム性とは若干異なる。アクションゲームでは特に、多少正確さを削いだとしても素早い判断が求められる場面がより多く存在するだろう。AI自身が臨機応変にそれを切り替えながら動作できるとしたら、ゲームへの応用という分野において大きなブレークスルーが起こるのかもしれない。
今回紹介したGamingAgentは、GitHubにてMITライセンスで公開されている。


この記事にはアフィリエイトリンクが含まれる場合があります。
