
DeepMindのAIが『StarCraft II』のプロプレイヤーに10勝1敗。条件によっては、ゲームでもAIが人間に勝てる時代に
DeepMindの強化学習エージェント「AlphaStar」が『StarCraft II』のプロプレイヤーに圧勝。DeepMindとBlizzardの提携のもと2016年より研究が進められていた『StarCraft II』の深層強化学習の成果である。
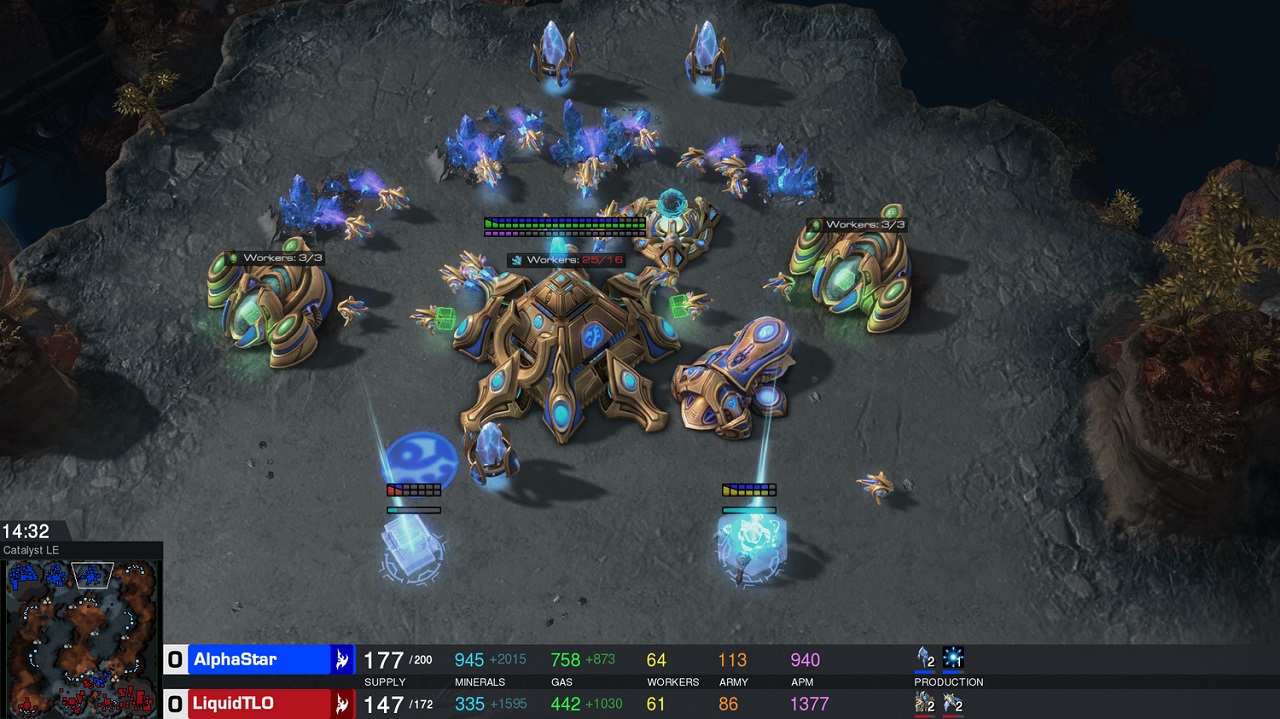
Google傘下のDeepMind Technologies(以下、DeepMind)とBlizzard Entertainment(以下、Blizzard)の提携により研究が進められている『StarCraft II』の深層強化学習。そのひとつの成果として、同作における対戦モードでAIが人間のプロプレイヤーに勝利したことが報告されている。具体的には、深層強化学習エージェント「AlphaStar」が、『StarCraft II』のプロ選手として活動しているTeam Liquid所属のTLO氏(本名:Grzegorz Komincz)およびMaNa氏(本名:Dario Wünsch)に対し、合計10勝1敗という圧倒的な戦績をおさめている。
2017年8月にDeepMind/Blizzardが機械学習の研究用ツールを一般公開した際には、『StarCraft II』を使った研究の長期目標はプロゲーマーに勝利することであると宣言されていた。今回AlphaStarの活躍により、その長期目標が1年半足らずで達成された形となる。2018年12月に始まったAlphaStar対プロプレイヤーの企画は12月に始まった。トッププレイヤーのひとりであるTLO氏およびMaNa氏とそれぞれ5マッチずつ対戦するというもので、両者ともAlphaStarに対し全敗した。そして今回MaNa氏が再戦に挑み、1月に配信されたエキシビジョン・マッチにてようやく1勝をもぎとった。
AlphaStarの反応速度・操作量は人間レベルに制限
ただし、TLO氏が一番得意としている種族はZerg。一方でAlphaStarとの対戦ではエージェントの学習状況の都合上、Protossを使用している。TLO氏がフルポテンシャルを出せる条件ではなかったことには留意が必要だろう。上の動画でもTLO氏は、Zergを使えば勝てると思うと自信を覗かせている。そうした事情もあって、2人目の対戦相手としてはProtoss使いのMaNa氏が選ばれたわけだが、それでも当初の5連戦では勝ち星をあげることができなかった。動画では、人間であるMaNa氏の方が「AlphaStarから新しい戦い方を学習している気分だ」と感想を述べている。
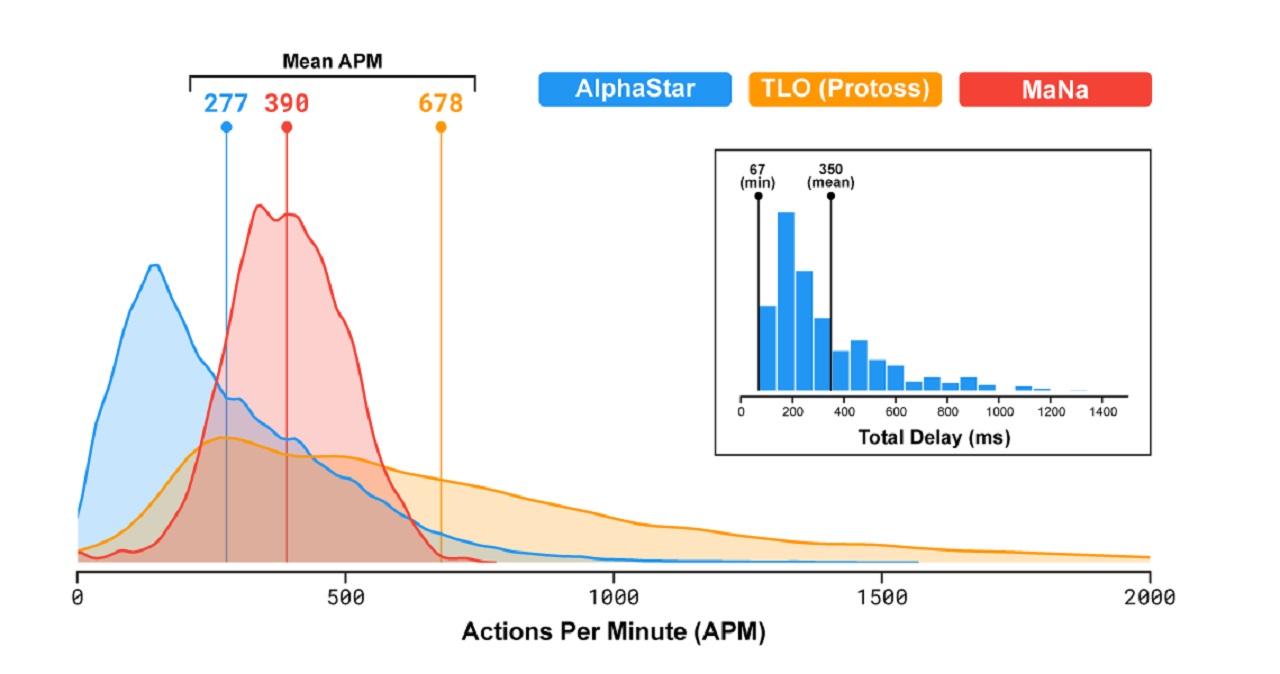
一方のAlphaStar側は、できる限りフェアな対戦条件を揃えるため、反応速度やAPM(1分間あたりの操作量)が人間と同等のレベルにおさえられている(プロの平均以下)。ただし最初の10戦では、人間プレイヤーと違いマップ全域を常時見渡せるよう設定されていた(Fog of war部分は人間と同じく不可視)。MaNa氏が勝利した最後の1戦に限り、人間と同じカメラ設定でのマッチに挑戦している。最後の1戦として人間と同じカメラ設定で戦うにあたっては、学習期間が限られていたこともあり、時間が経てばまた異なる結果が出ることだろう。
DeepMindの研究材料として『StarCraft II』が選ばれた理由としては、同作が素早い判断能力、難解な局面の把握、不確実性を考慮した問題解決、長期的な視点による計画力など複雑な情報処理が求められることがあげられる。そもそもゲームを研究材料として選んでいる理由としては、勝敗やスコアといった成果を図るための指標が明確であることはもちろんのこと、プレイヤー人口が多い作品であればあるほど大量の観測用データを確保しやすいというメリットが挙げられる。
※11戦目、MaNa選手 vs AlphaStarのライブ配信アーカイブ
驚異的な学習速度
研究の途中経過が公表された2017年8月時点では、ゲームに実装されている最低レベルのAI相手にも苦戦しているレベルであり、エージェントがトッププレイヤーを超えるにはまだまだ時間を要するとの予想がたてられていた(関連記事)。だが2018年に入って学習アプローチを変えることで学習速度が大幅に向上。まず各エージェントにゲーム内の特定の要素・特定の戦術を集中的に学んでもらうためのデータを与え、エージェントごとに異なる学習目標を設定する。専門分野を持つエージェントを大量に生み出すわけだ。そして特定分野に特化して成熟したエージェント同士を対戦させることで、学習速度を一気に上げるという手法である。数千もの強化学習エージェントが並行して強化学習を行う手順は、『Quake III Arena』における研究で採用された「Population-Based Deep Reinforcement Learning」でもその成果が確認されている(関連記事)。
このエージェント同士の対戦は2週間にわたり継続され、その間に1つのエージェントにつき200年分のマッチをプレイしたという。そして2018年12月、ついにDeepMind社内で一番うまい『StarCraft II』プレイヤーに勝利。その次なるステップとしてプロプレイヤーとのマッチを組み、見事勝利をおさめた。なおプロとの5連戦に使用されたのは、無数に存在するエージェントのうち、もっとも完成度が高いと判断された5つのエージェントである。
Go、Zero、そしてStarへ
DeepMindといえば、学習アルゴリズム「DQN(Deep Q-Network)」や囲碁対戦用プログラム「AlphaGo」が有名だ。DQNはゲームを繰り返しプレイして学習するなかで、Atari2600のゲームにて短時間で人間プレイヤーのスコアを上回ることに成功。AlphaGoは2016年3月に開催された「Google DeepMind Challenge Match」にて、10数年にわたり囲碁の世界ランク上位に君臨してきた韓国の李世ドル九段との5番勝負に勝利している。AIが人間を上回ることは難しいとされてきた囲碁の世界において、AIとして初めてプロ棋士を下した。続いてDeepMindはチェス・将棋・囲碁用プログラムAlphaZeroを開発。今度は人間のデータから学習を始めるのではなく、外部からの事例データ「ゼロ」の状態から始めることで、エージェントが自分自身でどこまで素早く効率的に学習できるのかという観点から研究が進められた。
そして今回のAlphaStarは、AlphaGoやAlphaZeroが学習した囲碁やチェス以上に複雑な処理が求められる『StarCraft II』において、AIとして初めてトッププレイヤーを下すという目覚ましい成果をあげた。DeepMindの目標は、こうしたニューラルネットワーク・アーキテクチャや深層強化学習の研究を、医療やエネルギー、AI、言語研究といった現実世界の複雑な問題に対処するために応用すること。AlphaStarの事例からは、そうした研究の成果がDeepMindの予想すら超えるスピードで進んでいることがうかがえる。快進撃を続けるAlphaシリーズの次なる挑戦ははたしてどのようなものになるのだろうか。
AlphaStarの『StarCraft II』学習過程をより詳しく知りたい方は、DeepMindの公式ブログを参考に。vsTLO、vsMaNa戦のリプレイ映像を確認したい方はこちら。
【UPDATE 2019/1/25 20:00】
記事タイトルを、より本文の内容に近いものに変更しました。
この記事にはアフィリエイトリンクが含まれる場合があります。
