
Google・DeepMindの新たなAIがFPS『Quake III Arena』にて人間以上のチームワークを発揮。シンギュラリティへの序章となるか
とあるAIに関する成果発表がソーシャルメディアを中心に注目を浴びている。2018年7月3日(現地時間)、米Google傘下のDeepMind TechnologiesがFPS『Quake III Arena』を使用した人工知能の強化学習開発の成果を発表したのだ。

とあるAIに関する成果発表がソーシャルメディアを中心に注目を浴びている。2018年7月3日(現地時間)、米Google傘下のDeepMind Technologies(以下、DeepMind)がFPS『Quake III Arena』を使用した人工知能(以下、AI)の強化学習開発の成果を発表したのだ。
Our latest work allows agents to reach human-level on Quake III Arena Capture the Flag through new multi-agent RL techniques: populations of agents learning their own internal reward signal and operating at multiple timescales https://t.co/phXmGFoIkK pic.twitter.com/P3KW908ljq
— Google DeepMind (@GoogleDeepMind) July 3, 2018
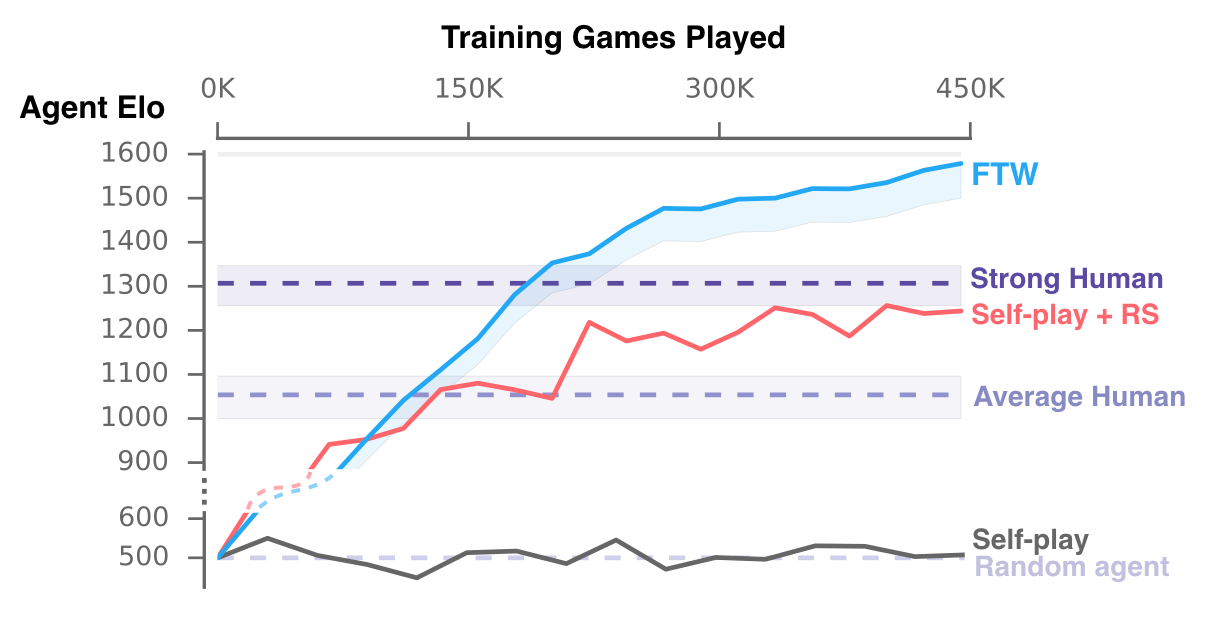
人間(を超える)レベルでFPSをプレイ
AIと人間をゲーム内で対戦させることで、AI技術、社会的認知の向上を狙うDeepMindの活動は以前にもご紹介した。『StarCraft』による訓練 のかたわら、新規プロジェクトとして、チーム構成と対戦相手の多様性を学習することを目指す強化学習(Reinforcement Learning)をスタートさせていた。その成果報告として、同AIが『Quake III Arena』のキャプチャー・ザ・フラッグ(以下、CTF)というモードで、人間との協力プレイにおいて、AIが人間レベルの成績を達成したという。
FPSである『Quake III Arena』はリアルタイムでゲームが進行する。目先の状況はもちろん、視野外を判断するには難しい一人称視点の作品だ。CTFではそれぞれのプレイヤーが旗を奪取、またそれらの阻止を狙い、ダイナミックに移動しなければならない。非常に複雑な操作と瞬発力が必要とされるモードである。
強化学習開発は以下のような流れとなる。
まずこの実験では、数千もの強化学習エージェントが並行して学習行動を取る「Population-Based Deep Reinforcement Learning (学術報告書)」という手法が採用されている。エージェント同士の2対2の対戦プレイで、互いに交流・協力しながらプレイ方法を習得。単体ではなく、大量のエージェントに同時並行で学習させることで多様性が生まれ、学習効果を高められるという狙いだ。
そして実験を進めていく中で、エージェントは独自に物事を解釈し行動パターンを増やしていく。ゲームのルールを理解したあとは、何に価値を置いて行動すべきなのか、どういう行動を取れば勝利しやすいのか、「フラッグを確保する」「敵を見つけた」といった独自の内部報酬を生成し始める。この学習方法によりCTFルールを習得していったエージェントは、For The Win(以下、FTW)エージェントと呼ばれている。
だがこうしたFTW同士の学習だけでは行動パターンが人間に比べ非常に少なく、スキルが思うように向上しなかった。その後Deepmindは、40人の実際の人間を含むトーナメント戦で、エージェントをチームメイトや対戦相手としてランダムにマッチングさせた。そうした対人間戦による強化学習にて、FTWエージェントは上位プレイヤーよりも速くスキルを伸ばすことができたという。
強化学習プログラムの背景となるDeepMindの理念は、OpenAIが『Dota 2』用にBOTを作り出し、チームプレイを教える手法に近い(参考記事)。DeepMindの焦点は「チーム構成と対戦相手の多様性」の2つにある。
FTWエージェントは、複数人同時に訓練をした結果、エージェント同士で協力し合うようになり、グループ内の人間を上回る結果を出し始めたという。さらに『Dota 2』でのAIと同様、拠点に引きこもるベースキャンピングといった戦略を取り始めたのだ。なおDeepMindはこのFTWエージェントを用いた実験において、プレイごとにマップを書き換えることで、新たな戦略をAIが独自に学ばなければならないようプログラムに手を加えている。

FTWエージェントはランダムに変化するマップを解析し、敵と味方の動きを把握する必要がある。上図は、FTWのアーキテクチャの概念図だ。高速、低速のタイムスケールでリカレントニューラルネットワーク(RNN※)を結合、そして共有メモリモジュールを含み、ゲームポイントから内部報酬への変換を学習させている。つまり、RNNが出力した画像から抽出した情報と、そのラウンドでのゲーム情報に強化学習を適応させ、次の戦略、行動をAIが独自に決定しているのだ(※RNNについてはこちらを参照)。
DeepMindは公式ブログでの報告を、「今回発表した論文はCTFを用いた実験にフォーカスしているが、この研究成果は普遍的である。私達が公開した手法を用いて他の人々が、さらに複雑な環境で何かを構築することを期待している。そして将来的には、現在の強化学習とFTWエージェントの集団訓練方法を改善していきたい」との言葉で締めている。
人間の知性を解明すること
これはDeepMindの公式サイトにある企業理念だ。DeepMindの共同設立者であり最高経営責任者(以下、CEO)であるデミス・ハサビス(Demis Hassabis)氏は、汎用人工知能(Artificial General Intelligence:AGI)を実現させるプロセスは、「数十年にわたる宇宙開発と人類の大きな一歩が踏み出されたアポロ計画のようなものだ」と述べている。それはAIに人間の言語を理解させることや、人間の指示に従わせるといったレベルのものではない。ハサビス氏が開発しようとしているのは、脳神経科学と機械科学との考察をベースとした、どのような状況に置かれても人間と同じ思考能力、判断能力を下せるAIであるという。
こうしたDeepMindの姿勢に対して、「知性をもつAIが人類の絶滅を早める可能性があるかもしれない」と警告したのは、スウェーデン生まれ オックスフォード大学哲学教授であるニック・ボストロム(Nick Bostrom)氏。彼のベストセラーである『Superintelligence : Paths, Dangers, Strategies』では「私はGoogleの囲碁AI『Alpha Go』(関連記事)のようなAIを軽視しているわけではないが、それが必ずしも人類にとって大きな飛躍をもたらすものではない。」と主張している。
能力と資本をもつ大勢が、AIが人間を超える所謂「シンギュラリティ」に向かい躍起になっているこの時代。AI研究分野においてそれは非常に重要なことであるが、そうした運動に警鐘を鳴らす人たちも少なからずいるのも事実だ。 今回のDeepMindによる成果発表を見れば、AI学習はもはやルールを記述する必要がなくなったことを示している。AIの学習能力はその姿を変えつつある。これらの事実がシンギュラリティへの序曲となるか。人類にとってより良い未来を暗示することになるのか。時代が進めば、徐々にその答えがわかってくるだろう。



この記事にはアフィリエイトリンクが含まれる場合があります。

Yu Naganeo
記事本文: 61